ĪĪĪĪįŁ╬─üĒį┤Ż║AIGCķ_Ę┼╔ńģ^
ĪĪĪĪ╬─╔·łDŅIė“ę╗ų▒├µ┼Rų°ę╗éĆ║╦ą─ļyŅ},Š═╩ŪėąŚl╝■łDŽ±╔·│╔Ą─ą¦╣¹Ż¼▀h│¼¤oŚl╝■Ą─łDŽ±╔·│╔ĪŻėąŚl╝■łDŽ±╔·│╔╩ŪųĖ─Żą═į┌╔·│╔łDŽ±Ą─▀^│╠ųą,Ģ■Ņ~═Ō╩╣ė├ŅÉäeĪó╬─▒ŠĄ╚▌oų·ą┼Žó▀MąąųĖī¦,▀@śė┐╔ęįĖ³║├Ą─└ĒĮŌė├æ¶Ą─╬─▒ŠęŌłDŻ¼╔·│╔Ą─łDŽ±┘|┴┐ę▓Ė³Ė▀ĪŻ
ĪĪĪĪČ°¤oŚl╝■łDŽ±╔·│╔═Ļ╚½╗∙ė┌─Żą═ūį╝║īW┴ĢĄ─öĄō■Ęų▓╝,ļyęįą╬│╔ėąą¦Ą─ųĖī¦Ż¼╦∙ęįŻ¼╬ęéāĮø│ŻĢ■ėąĄ─AIŲĮ┼_╔·│╔Ą─łDŽ±¾H┤Į▓╗ī”±RūņŻ¼╗“š▀łDŽ±ėąųž┤¾╚▒Ž▌ĪŻ
ĪĪĪĪ×ķ┴╦ĮŌøQ▀@éĆå¢Ņ},┬ķ╩Ī└Ē╣żīWį║║═MetaĄ─AI蹊┐╚╦åTķ_░l┴╦RCG─Żą═(Representation-Conditioned imageGeneration)ĪŻ
ĪĪĪĪRCG╩Ūę╗ĘNäōą┬ąįĄ─“╗∙ė┌▒Ē╩ŠŚl╝■Ą─łDŽ±╔·│╔”─Żą═ĪŻ╦∙ų^“▒Ē╩ŠŚl╝■”,Š═╩Ūūī─Żą═ūį╝║Å─öĄō■ųą╠ß╚Ī▒Ē╩ŠüĒ▀MąąųĖī¦Ż¼Č°¤oąĶ╚╬║╬╚╦╣żöĄō■ś╦ūóĪŻ╦∙ęįŻ¼RCG─▄ęįĖ³ąĪĄ─Ž¹║─Ż¼╔·│╔┼cėąųĖī¦─Żą═ŽÓµŪ├└Ą─łDŲ¼ĪŻ
ĪĪĪĪķ_į┤ĄžųĘŻ║
ĪĪĪĪšō╬─ĄžųĘŻ║
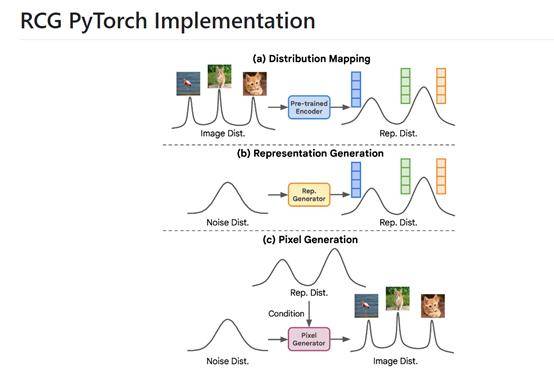
ĪĪĪĪÅ─RCGĄ─šō╬─üĒ┐┤Ż¼ŲõłDŲ¼╔·│╔┴„│╠▓╔ė├┴╦öM╚╦╗»╦╝┬ĘĪŻŽ╚ęÄäØ│÷ę¬╔·│╔łDŲ¼Ą─┤¾¾w▌å└¬,╚╗║¾į┘Ė∙ō■▀@ę╗śŗ╦╝╚ź└LųŲłDŲ¼Ą─╝Ü╣ØĪŻ
ĪĪĪĪŠ═Ž±╬ęéā╚╦ŅÉ«ŗ«ŗę╗śė,Ž╚į┌┤¾─Xųąśŗ╦╝«ŗū„Ą─š¹¾w╦╝┬ĘŻ¼└²╚ńŻ¼Žļ«ŗę╗Ųź±R,Ž╚ŽļŽ¾±RĄ─ą╬¾w;Žļ«ŗę╗éĆ╠O╣¹,Ž╚ŽļŽ¾éĆ┤¾╝t╔½Ą─łAŪ“Ż¼╚╗║¾Ė∙ō■š¹¾w“▒Ē╩Š”«ŗ│÷łDŽ±Ą─╝Ü╣ØĪŻ
ĪĪĪĪłDŽ±ŠÄ┤aŲ„
ĪĪĪĪłDŽ±ŠÄ┤aŲ„Ą─ū„ė├╩ŪÅ─łDŽ±ųą╠ß╚ĪėąęŌ┴xĄ─▒Ē╩ŠĪŻ▀@ą®▒Ē╩Šį┌▒Ż┴¶łDŽ±Ą─šZ┴xą┼ŽóĄ─═¼Ģr,ę▓ę¬▒╚▌^║åå╬Īóęūė┌Į©─ŻĪŻ
ĪĪĪĪ─┐Ū░┴„ąąĄ─ūį▒OČĮīW┴Ģ╦ŃĘ©ų„ę¬┐╔ęįĘų×ķā╔┤¾ŅÉ:1)╗∙ė┌ŅAė¢ŠÜ╚╬䚯¼▀@ŅÉĘĮĘ©Ģ■╚╦×ķįOėŗę╗éĆŅAė¢ŠÜ╚╬äš,ūī─Żą═╚źŅA£yę╗ą®é╬ś╦║×ĪŻ▒╚╚ńą²▐DŅA£y╚╬äš,ūī─Żą═ŅA£yłDŽ±▒╗ą²▐DĄ─ĮŪČ╚Ą╚ĪŻ
ĪĪĪĪ2)╗∙ė┌ī”▒╚īW┴ĢŻ¼▀@ŅÉĘĮĘ©Ģ■śŗįņš²śė▒Š║═žōśė▒ŠĪŻūī─Żą═īWĢ■ģ^Ęų║═└Ł▀h╦³éāį┌▒Ē╩Š┐šķgĄ─ŠÓļxŻ¼┤·▒Ēąį╦ŃĘ©░³└©MoCoĪóSimCLRĄ╚ĪŻ
ĪĪĪĪīŹ“×ūC├„Ż¼╗∙ė┌ī”▒╚īW┴ĢĘĮĘ©Ż¼┐╔ęį½@Ą├Ė³╝ėėąą¦Ą─łDŽ±▒Ē╩Š,ę“┤╦RCG▀xō±┴╦▀@ĘNĘĮ╩ĮĪŻ▓ó╩╣ė├┴╦MoCo v3▀MąąŅAė¢ŠÜ,▀@╩ŪłDŽ±ĘųŅÉ╚╬äš╔Žą¦╣¹ūŅāץ─ūį▒OČĮī”▒╚īW┴Ģ╦ŃĘ©ų«ę╗ĪŻ
ĪĪĪĪ×ķ┴╦╩╣▒Ē╩ŠŠSČ╚┐╔┐ž,RCG╩╣ė├┴╦ĦėąŅA£yŅ^Ą─Transformer─Żą═ĪŻŅA£yŅ^Ģ■ęÄäØ│╔256ŠSĄ─Ž“┴┐,▀@śėŠ═½@Ą├┴╦ŠÄ┤aŲ„▌ö│÷Ą─▒Ē╩ŠĪŻįō▒Ē╩Š═¼Ģr▀Ć▀Mąą┴╦Üwę╗╗»╠Ä└Ē,ęįĘ¹║ŽĖ▀╦╣Ęų▓╝ĪŻ
ĪĪĪĪ▒Ē╩Š╔·│╔─ŻēK
ĪĪĪĪį┌╠ß╚ĪĄĮłDŽ±Ą─▒Ē╩Šų«║¾,Ž┬ę╗▓ĮŠ═╩Ūī”▀@ą®▒Ē╩Š▀Mąą▓╔śėĪŻ═©│Ż,╬ęéāŽŻ═¹─Żą═┐╔ęį▓ČūĮ▒Ē╩Š┐šķgĄ─Ęų▓╝,Š▀ėą╔·│╔Ė„ĘNą┬Ęf▒Ē╩ŠĄ──▄┴”,Å─Č°ųĖī¦Ž┬ė╬Ą─łDŽ±╔·│╔ĪŻ
ĪĪĪĪ×ķ┤╦,RCG╠ß│÷┴╦▒Ē╩ŠöU╔ó─Żą═RDMĪŻ╦³╩╣ė├╚½▀BĮėŠWĮjū„×ķų„Ė╔,░³║¼öĄéĆÜł▓ŅēKĪŻ├┐éĆēK└’├µ░³└©╝ż╗Ņ║»öĄĪóŠĆąįīėĄ╚ĪŻ
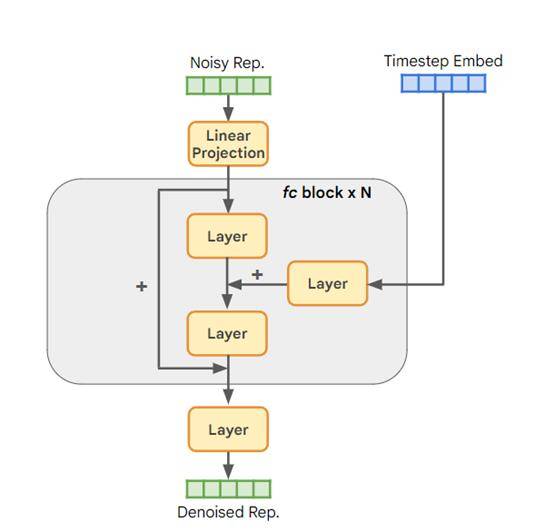
ĪĪĪĪRDM─ŻēKė¢ŠÜĢr,▓╔ė├┴╦DDIM╦ŃĘ©ĪŻ╝┤Ž╚īóšµīŹłDŽ±▒Ē╩Š╝ė╚ļĖ▀╦╣įļ┬Ģ,ūīRDM╚ź│²įļ▓óųžśŗįŁ╩╝▒Ē╩Š;╔·│╔Ģr,Å─═Ļ╚½įļ┬Ģ▒Ē╩Š│÷░l,ų▓Į▓╔śėŪÕ╬·Ą─▒Ē╩ŠĪŻ

ĪĪĪĪRDM─ŻēKĄ─ģóöĄ║═ėŗ╦Ń┴┐║▄ąĪ,╦∙ęį╝┤╩╣į÷╝ėēKöĄ║═īÆČ╚,ę▓▓╗Ģ■ĦüĒ╠½┤¾Ą─Ņ~═Ōžōō·ĪŻ▀@śė╬ęéā┐╔ęį│õĘų░lŠ“▒Ē╩Š┐šķgĄ─žSĖ╗ą┼Žó,ųĖī¦Ž┬ė╬╔·│╔ĪŻ
ĪĪĪĪŽ±╦ž╔·│╔Ų„
ĪĪĪĪ╠ß╚Ī▒Ē╩Š▓óī”ŲõĮ©─Żų«║¾,ūŅ║¾ę╗▓ĮŠ═╩ŪĖ∙ō■▒Ē╩ŠüĒ╔·│╔łDŽ±Ž±╦žĪŻRCGųąĄ─Ž±╦ž╔·│╔Ų„┐╔ęį╩╣ė├╚╬ęŌĄ─Śl╝■łDŽ±╔·│╔─Żą═,ų╗ąĶę¬īóįŁėąĄ─Śl╝■(▒╚╚ńŅÉäeś╦║×)╠µōQ×ķRDM╔·│╔Ą─▒Ē╩Š╝┤┐╔ĪŻ

ĪĪĪĪė¢ŠÜĢr,MAGEĮė╩šÄ¦ėąš┌▒╬(Mask)Ą─łDŽ±ū„×ķ▌ö╚ļ,ŲõųąÄ¦XĄ─╩Ū▒╗š┌▒╬Ą─Ż¼═¼Ģrę▓▌ö╚ļī”æ¬łDŽ±Ą─▒Ē╩Š,╚╗║¾īW┴Ģųžśŗ▒╗š┌▒╬Ą─ā╚╚▌ĪŻ
ĪĪĪĪ×ķ┴╦“×ūCRCG─Żą═Ą─ą¦╣¹,蹊┐łFĻĀ╗∙ė┌ImageNet£yįćŲĮ┼_ųąĄ─256×256öĄō■╝»▀Mąą┴╦īŹ“×ĪŻ

ĪĪĪĪĮY╣¹’@╩ŠŻ¼RCGĄ─FIDĘųöĄ×ķ3.56║═ISĄ─253.4Ż¼│¼▀^┴╦ų«Ū░ūŅ║├Ą─¤oŚl╝■╔·│╔─Żą═MAGEĄ─ĮY╣¹,┼c«öŪ░ĀŅæBūŅ║├Ą─ėąŚl╝■─Żą═CDM▓Ņ▓╗ČÓĪŻ
ĪĪĪĪ╬─š┬ā╚╚▌āH╣®ķåūxŻ¼▓╗śŗ│╔═Č┘YĮ©ūhŻ¼šłųö╔„ī”┤²ĪŻ═Č┘Yš▀ō■┤╦▓┘ū„Ż¼’LļUūįō·ĪŻ
║Żł¾╔·│╔ųą...

║Ż╦ćAIĄ──Żą═ŽĄĮyį┌ć°ļH╩ął÷╔ŽÅV╩▄║├įuŻ¼─┐Ū░šŠā╚└█ėŗ─Żą═öĄ│¼▀^80╚féĆŻ¼║Ł╔wīæīŹĪóČ■┤╬į¬Īó▓Õ«ŗĪóįOėŗĪóözė░Īó’LĖ±╗»łDŽ±Ą╚ČÓŅÉą═æ¬ė├ł÷Š░Ż¼╗∙▒ŠĖ▓╔w╦∙ėąų„┴„äōū„’LĖ±ĪŻ

9į┬9╚šŻ¼ć°ļHÖÓ═■╩ął÷š{čąÖCśŗėóĖ╗┬³(Omdia)░l▓╝┴╦ĪČųąć°AIįŲ╩ął÷Ż¼1H25ĪĘł¾ĖµĪŻųąć°AIįŲ╩ął÷░ó└’įŲš╝▒╚8%╬╗┴ąĄ┌ę╗ĪŻ

9į┬24╚šŻ¼╚A×ķ└żņ`š┘ķ_Ī░ųŪ─▄¾w“ׯ¼ę╗Ų┴ĄĮ╬╗Ī▒╚A×ķIdeaHubŪ¦ąą░┘śI¾w“×╣┘ėŗäØ░l▓╝Ģ■ĪŻ

č┼±R╣■ū“╚šą¹▓╝═Ų│÷ā╔┐ŅŅ^┤„╩ĮČ·ÖCŻ¼Ęųäe╩ŪŲĮ░Õš±─żĄ─YH-4000║═äė╚”įŁ└ĒĄ─YH-C3000ĪŻ

IDCĮ±╚š░l▓╝Ą─ĪČ╚½Ū“ųŪ─▄╝ęŠėŪÕØŹÖCŲ„╚╦įOéõ╩ął÷╝ŠČ╚Ė·█Öł¾ĖµŻ¼2025─ĻĄ┌Č■╝ŠČ╚ĪĘ’@╩ŠŻ¼╔Ž░ļ─Ļ╚½Ū“ųŪ─▄╝ęŠėŪÕØŹÖCŲ„╚╦╩ął÷│÷žø1,2╚f┼_Ż¼═¼▒╚į÷ķL33%Ż¼’@╩Š│÷ŲĘŅÉÅŖä┼Ą─╩ął÷ąĶŪ¾ĪŻ


ĘĄ╗žų„Ēō ®« ĻPė┌╬ęéā ®« ā╚╚▌┬ōŽĄ ®« ┬ōŽĄ╬ęéā ®« ├Ōž¤┬Ģ├„ ®« įŁäōą┬┬ä ®« ķTæ¶░µ
Copyright www.9c1h.cn ųą╬─┐Ų╝╝┘YėŹ 2009-2025 all rights reserved ŠWšŠ┬ōŽĄ╬óą┼ xishuinet
ĻPµIį~Ż║CITNews|Citnewsųą╬─┐Ų╝╝┘YėŹ|ųą╬─┐Ų╝╝┘YėŹŠW|┐Ų╝╝┘YėŹŠW|ųąć°┐Ų╝╝┘YėŹ|ųąć°┐Ų╝╝ą┬┬äŠW|ųąć°┐Ų╝╝┘YėŹŠW|┐ņ┐Ų╝╝|ą┬┐Ų╝╝|ųą╬─┐Ų╝╝öĄ┤aŅ^Śl╠¢|ųą╬─ęŲäėą┬├Į¾w