ĪĪĪĪüĒį┤Ż║ā╚(n©©i)╚▌ŠÄūgūįtheregisterĪŻ
ĪĪĪĪ╚ń╣¹─·šJ(r©©n)×ķ╚╦╣żųŪ─▄ŠW(w©Żng)Įj(lu©░)▀Ć▓╗ē“Å═(f©┤)ļsŻ¼─Ū├┤ NvidiaĪóAMD ║═ėó╠žĀ¢Ą╚╣½╦Š═Ų│÷Ą─ÖC(j©®)╝▄╩Į╝▄śŗ(g©░u)īóĦüĒą┬Ą─Å═(f©┤)ļsąįĪŻ
ĪĪĪĪ┼c═©│Ż╩╣ė├ęį╠½ŠW(w©Żng)╗“ InfiniBand Ą─ÖMŽ“öU(ku©░)š╣ŠW(w©Żng)Įj(lu©░)ŽÓ▒╚Ż¼▀@ą®ŽĄĮy(t©»ng)║╦ą─Ą─┐vŽ“öU(ku©░)š╣ĮY(ji©”)śŗ(g©░u)═©│Ż▓╔ė├īŻėąĄ─╗“ų┴╔┘╩Ūą┬┼dĄ─╗ź▀B╝╝ąg(sh©┤)Ż¼┐╔×ķ├┐éĆ(g©©)╝ė╦┘Ų„╠ß╣®ÄūéĆ(g©©)öĄ(sh©┤)┴┐╝ē(j©¬)Ą─Ė³Ė▀ĦīÆĪŻ
ĪĪĪĪ└²╚ńŻ¼Nvidia Ą─Ą┌╬Õ┤· NVLink ╗ź▀B×ķ├┐éĆ(g©©)╝ė╦┘Ų„╠ß╣®▒╚«ö(d©Īng)Į±ęį╠½ŠW(w©Żng)╗“ InfiniBand Ė▀ 9 ▒ČĄĮ 18 ▒ČĄ─┐éĦīÆĪŻ
ĪĪĪĪ▀@ĘNĦīÆęŌ╬Čų° GPU Ą─ėŗ(j©¼)╦Ń║═ā╚(n©©i)┤µ┐╔ęį│ž╗»Ż¼╝┤╩╣╦³éā╬’└Ē╔ŽĘų▓╝į┌ČÓéĆ(g©©)▓╗═¼Ą─Ę■äš(w©┤)Ų„╔ŽĪŻNvidia ╩ūŽ»ł╠(zh©¬)ąą╣┘³S╚╩äūīó GB200 NVL72 ĘQ×ķ“ę╗ēKŠ▐ą═ GPU”Ż¼▀@┐╔▓╗╩Ūķ_═µą”ĪŻ
ĪĪĪĪŽ“▀@ą®ÖC(j©®)╝▄ęÄ(gu©®)─Ż╝▄śŗ(g©░u)Ą─▐D(zhu©Żn)ūāį┌║▄┤¾│╠Č╚╔Ž╩▄ĄĮ OpenAI ║═ Meta Ą╚─Żą═śŗ(g©░u)Į©š▀Ą─ąĶŪ¾Ą─═Ųäė(d©░ng)Ż¼╦³éāų„ę¬ßśī”(du©¼)│¼┤¾ęÄ(gu©®)─ŻįŲ╠ß╣®╔╠ĪóCoreWeave ╗“ Lambda Ą╚ą┬įŲ▀\(y©┤n)ĀI╔╠ęį╝░ąĶę¬īóŲõ AI ╣żū„žō(f©┤)▌d▒Ż┴¶į┌▒ŠĄžĄ─┤¾ą═Ų¾śI(y©©)ĪŻ
ĪĪĪĪ┐╝æ]ĄĮ▀@éĆ(g©©)─┐ś╦(bi©Īo)╩ął÷Ż¼▀@ą®ÖC(j©®)Ų„Ą─ār(ji©ż)Ė±▓╗ĘŲĪŻō■(j©┤)The Next Platform ╣└ėŗ(j©¼)Ż¼å╬éĆ(g©©) NVL72 ÖC(j©®)╝▄Ą─│╔▒Š×ķ 350 ╚f├└į¬ĪŻ
ĪĪĪĪąĶę¬├„┤_Ą─╩ŪŻ¼īŹ(sh©¬)¼F(xi©żn)▀@ą®ÖC(j©®)╝▄╝ē(j©¬)╝▄śŗ(g©░u)Ą─┐vŽ“öU(ku©░)š╣╝▄śŗ(g©░u)▓óĘŪą┬§r╩┬╬’ĪŻų╗╩ŪĄĮ─┐Ū░×ķų╣Ż¼╦³éā║▄╔┘öU(ku©░)š╣ĄĮå╬éĆ(g©©)╣Ø(ji©”)³c(di©Żn)ų«═ŌŻ¼▓óŪę═©│ŻūŅČÓų¦│ų 8 éĆ(g©©) GPUĪŻ└²╚ńŻ¼ęįŽ┬╩Ū AMD ūŅą┬░l(f©Ī)▓╝Ą─MI350 ŽĄ┴ąŽĄĮy(t©»ng)ųąĄ─┐vŽ“öU(ku©░)š╣╝▄śŗ(g©░u)ĪŻ
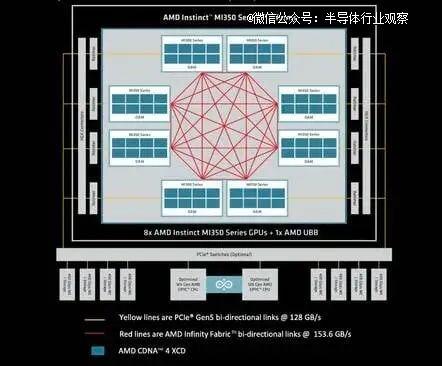
ĪĪĪĪ╚ń─·╦∙ęŖŻ¼├┐éĆ(g©©)ąŠŲ¼Č╝ęį╚½ī”(du©¼)╚½═ž?f©┤)õĮY(ji©”)śŗ(g©░u)▀BĮėŲõ╦¹Ų▀éĆ(g©©)ąŠŲ¼ĪŻ
ĪĪĪĪNvidia Ą─ HGX įO(sh©©)ėŗ(j©¼)čžė├┴╦Ųõ╦─ GPU *** ŽĄĮy(t©»ng)Ą─╗∙▒Š─Ż░ÕŻ¼Ą½×ķŲõĖ³│ŻęŖĄ─░╦éĆ(g©©) GPU ╣Ø(ji©”)³c(di©Żn)į÷╝ė┴╦╦─éĆ(g©©) NVLink Į╗ōQÖC(j©®)ĪŻļm╚╗ Nvidia▒Ē╩Š▀@ą®Į╗ōQÖC(j©®)Ą─║├╠Ä╩Ū┐╔ęį┐sČ╠═©ą┼Ģr(sh©¬)ķgŻ¼Ą½ę▓į÷╝ė┴╦Å═(f©┤)ļsąįĪŻ
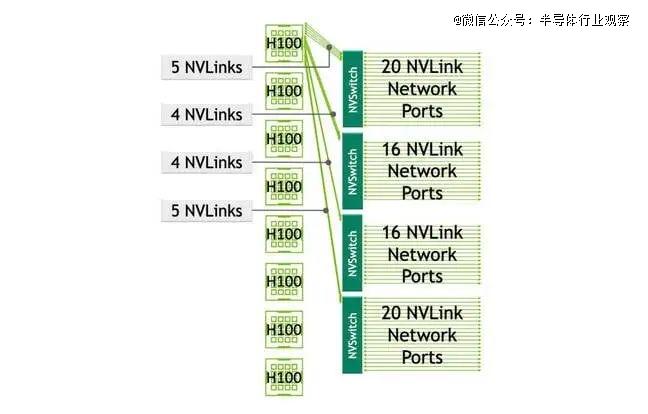
ĪĪĪĪļSų°Ž“ÖC(j©®)╝▄ęÄ(gu©®)─ŻĄ─▐D(zhu©Żn)ūāŻ¼═¼śėĄ─╗∙▒Š═ž?f©┤)õĮY(ji©”)śŗ(g©░u)ų╗╩Ū║åå╬Ąž?c©ói)U(ku©░)┤¾┴╦ęÄ(gu©®)─Ż——ų┴╔┘ī”(du©¼)ė┌ Nvidia Ą─ NVL ŽĄĮy(t©»ng)Č°čį╩Ū╚ń┤╦ĪŻī”(du©¼)ė┌ AMD üĒšfŻ¼╚½ŠW(w©Żng)ĀŅŠW(w©Żng)Įj(lu©░)Ė∙▒Š▓╗ē“ė├Ż¼Į╗ōQÖC(j©®)ūāĄ├▓╗┐╔▒▄├ŌĪŻ
ĪĪĪĪ01
ĪĪĪĪ╔Ņ╚ļ╠ĮŠ┐ Nvidia Ą─ NVL72 öU(ku©░)š╣╝▄śŗ(g©░u)
ĪĪĪĪ╬ęéā╔į║¾Ģ■(hu©¼)╔Ņ╚ļ╠Įėæ House of Zen ╝┤īó═Ų│÷Ą─ Helios ÖC(j©®)╝▄Ż¼Ą½╩ūŽ╚╬ęéāŽ╚üĒ┐┤┐┤ Nvidia Ą─ NVL72ĪŻė╔ė┌╦³╔Ž╩ąĢr(sh©¬)ķg▌^Č╠Ż¼╬ęéāī”(du©¼)╦³┴╦ĮŌĄ├▒╚▌^ČÓĪŻ
ĪĪĪĪ║åå╬╗žŅÖę╗Ž┬Ż¼įōÖC(j©®)╝▄╩ĮŽĄĮy(t©»ng)ōĒėą72 éĆ(g©©) Blackwell GPUŻ¼Ęų▓╝į┌ 18 éĆ(g©©)ėŗ(j©¼)╦Ń╣Ø(ji©”)³c(di©Żn)╔ŽĪŻ╦∙ėą▀@ą® GPU Č╝═©▀^ 18 éĆ(g©©) 7.2TB/s Ą─ NVLink 5 Į╗ōQąŠŲ¼▀BĮėŻ¼▀@ą®ąŠŲ¼│╔ī”(du©¼)▓┐╩į┌ 9 éĆ(g©©)ĄČŲ¼Ę■äš(w©┤)Ų„╔ŽĪŻ
ĪĪĪĪō■(j©┤)╬ęéā┴╦ĮŌŻ¼├┐éĆ(g©©)Į╗ōQÖC(j©®)ASICČ╝ōĒėą72éĆ(g©©)Č╦┐┌Ż¼├┐éĆ(g©©)Č╦┐┌Ą─ļpŽ“ĦīÆ×ķ800Gbps╗“100GB/sĪŻ┼c┤╦═¼Ģr(sh©¬)Ż¼NvidiaĄ─Blackwell GPUōĒėą1.8TB/sĄ─┐éĦīÆŻ¼Ęų▓╝į┌18éĆ(g©©)Č╦┐┌╔Ž——ÖC(j©®)╝▄╔ŽĄ─├┐éĆ(g©©)Į╗ōQÖC(j©®)ę╗éĆ(g©©)Č╦┐┌ĪŻūŅĮKĄ─═ž?f©┤)õĮY(ji©”)śŗ(g©░u)┐┤ŲüĒėą³c(di©Żn)Ž±▀@śėŻ║

ĪĪĪĪ▀@ĘNĖ▀╦┘╚½╗ź▀BĮY(ji©”)śŗ(g©░u)ęŌ╬Čų°ÖC(j©®)╝▄ųąĄ─╚╬║╬ GPU Č╝┐╔ęįįLå¢┴Ēę╗éĆ(g©©) GPU Ą─ā╚(n©©i)┤µĪŻ
ĪĪĪĪ02
ĪĪĪĪ×ķ╩▓├┤ę¬öU(ku©░)┤¾ęÄ(gu©®)─Ż?
ĪĪĪĪō■(j©┤) Nvidia ĘQŻ¼▀@ą®║Ż┴┐ėŗ(j©¼)╦Ńė“┐╔’@ų°╠ß╔² GPU Ą─▀\(y©┤n)ąąą¦┬╩ĪŻī”(du©¼)ė┌ AI ė¢(x©┤n)ŠÜ╣żū„žō(f©┤)▌dŻ¼▀@╝ę GPU Š▐Ņ^╣└ėŗ(j©¼)Ųõ GB200 NVL72 ŽĄĮy(t©»ng)Ą─╦┘Č╚▒╚═¼Ą╚öĄ(sh©┤)┴┐Ą─ *** ŽĄĮy(t©»ng)┐ņ 4 ▒ČŻ¼▒M╣▄į┌ŽÓ═¼Š½Č╚Ž┬Ż¼ĮM╝■ąŠŲ¼Ą─ąį─▄āHĖ▀│÷ 2.5 ▒ČĪŻ
ĪĪĪĪ═¼Ģr(sh©¬)Ż¼ī”(du©¼)ė┌═Ų└ĒŻ¼Nvidia▒Ē╩ŠŲõÖC(j©®)╝▄ęÄ(gu©®)─Ż┼õų├Ą─╦┘Č╚╠ßĖ▀┴╦ 30 ▒Č——▓┐ĘųįŁę“╩Ū┐╔ęį▓╔ė├▓╗═¼│╠Č╚Ą─öĄ(sh©┤)ō■(j©┤)Īó╣▄Ą└ĪóÅł┴┐║═īŻ╝ę▓óąąąįüĒ└¹ė├╦∙ėąā╚(n©©i)┤µÄ¦īÆŻ¼╝┤╩╣─Żą═▓╗ę╗Č©╩▄ęµė┌╦∙ėąā╚(n©©i)┤µ╚▌┴┐╗“ėŗ(j©¼)╦ŃĪŻ
ĪĪĪĪįÆļm╚ń┤╦Ż¼Nvidia ╗∙ė┌ Grace-Blackwell Ą─ÖC(j©®)╝▄ųą VRAM ×ķ 13.5TB ĄĮ 20TBŻ¼AMD ╝┤īó═Ų│÷Ą─ Helios ÖC(j©®)╝▄ųą VRAM ×ķ 30TB ū¾ėęŻ¼▀@ą®ŽĄĮy(t©»ng)’@╚╗╩Ū×ķĘ■äš(w©┤)ė┌Ž± Meta(’@╚╗ęččė▀t)ā╔╚fā|ģóöĄ(sh©┤)Ą─ Llama 4 Behemoth ▀@śėĄ─│¼┤¾─Żą═Č°įO(sh©©)ėŗ(j©¼)Ą─Ż¼╦³īóąĶę¬ 4TB ā╚(n©©i)┤µ▓┼─▄į┌ BF16 ╔Ž▀\(y©┤n)ąąĪŻ
ĪĪĪĪ▓╗āH─Żą═įĮüĒįĮ┤¾Ż¼╔ŽŽ┬╬─┤░┐┌(┐╔ęįīóŲõęĢ×ķ LLM Ą─Č╠Ų┌ėøæø)ę▓įĮüĒįĮ┤¾ĪŻ└²╚ńŻ¼Meta Ą─ Llama 4 Scout ōĒėą 1090 ā|éĆ(g©©)ģóöĄ(sh©┤)Ż¼▓ó▓╗╦Ń╠žäe┤¾——į┌ BF16 ╝ē(j©¬)äe╔Ž▀\(y©┤n)ąąĢr(sh©¬)āHąĶę¬ 218GB Ą─ GPU ā╚(n©©i)┤µĪŻ╚╗Č°Ż¼Ųõ 1000 ╚féĆ(g©©) token Ą─╔ŽŽ┬╬─┤░┐┌ätąĶę¬öĄ(sh©┤)▒Čė┌┤╦Ą─ā╚(n©©i)┤µŻ¼ė╚Ųõ╩Ūį┌┼·┴┐┤¾ąĪ▌^┤¾Ą─ŪķørŽ┬ĪŻ
ĪĪĪĪ03
ĪĪĪĪ═Ų£y AMD ╩ū ┐ŅöU(ku©░)š╣ŽĄĮy(t©»ng) Helios
ĪĪĪĪ║┴¤oę╔å¢Ż¼▀@Š═╩Ū×ķ╩▓├┤ AMD ę▓į┌Ųõ MI400 ŽĄ┴ą╝ė╦┘Ų„ųą▓╔ė├┴╦ÖC(j©®)╝▄╩Į╝▄śŗ(g©░u)ĪŻ
ĪĪĪĪį┌▒Šį┬│§Ą─ Advancing AI ┤¾Ģ■(hu©¼)╔ŽŻ¼AMD░l(f©Ī)▓╝┴╦Helios ģó┐╝įO(sh©©)ėŗ(j©¼)ĪŻ║åČ°čįų«Ż¼įōŽĄĮy(t©»ng)┼c Nvidia Ą─ NVL72 ĘŪ│ŻŽÓ╦ŲŻ¼īóė┌├„─Ļ╔Ž╩ąŻ¼┼õéõ 72 éĆ(g©©) MI400 ŽĄ┴ą╝ė╦┘Ų„Īó18 éĆ(g©©) EPYC Venice CPU ęį╝░ AMD Ą─ Pensando Vulcano NICĪŻ
ĪĪĪĪĻP(gu©Īn)ė┌įōŽĄĮy(t©»ng)Ą─╝Ü(x©¼)╣Ø(ji©”)╚į╚╗║▄╔┘Ż¼Ą½╬ęéāų¬Ą└╦³Ą─öU(ku©░)š╣ĮY(ji©”)śŗ(g©░u)īó╠ß╣® 260TB/s Ą─┐éĦīÆŻ¼▓óīó═©▀^ęį╠½ŠW(w©Żng)é„▌öą┬┼dĄ─ UALinkĪŻ
ĪĪĪĪ╚ń╣¹─·▀Ć▓╗╩ņŽżŻ¼ą┬┼dĄ─ Ultra Accelerator Link ś╦(bi©Īo)£╩(zh©│n)╩Ū NVLink Ą─ķ_Ę┼╠µ┤·ĘĮ░ĖŻ¼▀mė├ė┌öU(ku©░)š╣ŠW(w©Żng)Įj(lu©░)ĪŻUltra Accelerator Link ┬ō(li©ón)├╦ūŅĮ³ė┌ 4 į┬░l(f©Ī)▓╝┴╦Ųõ╩ū éĆ(g©©)ęÄ(gu©®)ĘČĪŻ
ĪĪĪĪHelios ├┐ēK GPU Ą─ļpŽ“ĦīÆ╝s×ķ 3.6TB/sŻ¼▀@īó╩╣Ųõ┼c Nvidia Ą┌ ę╗┤· Vera-Rubin ÖC(j©®)╝▄╩ĮŽĄĮy(t©»ng)(ę▓īóė┌├„─Ļ═Ų│÷)ŽÓµŪ├└ĪŻų┴ė┌ AMD ┤“╦Ń╚ń║╬īŹ(sh©¬)¼F(xi©żn)▀@ę╗─┐ś╦(bi©Īo)Ż¼╬ęéāų╗─▄▓┬£y——╬ęéāę▓▀@├┤ū÷┴╦ĪŻ

ĪĪĪĪĖ∙ō■(j©┤)╬ęéāį┌ AMD ų„Ņ}č▌ųvųą┐┤ĄĮĄ─ā╚(n©©i)╚▌Ż¼įōŽĄĮy(t©»ng)ÖC(j©®)╝▄╦Ų║§┼õéõ┴╦╬ÕéĆ(g©©)Į╗ōQĄČŲ¼Ż¼├┐éĆ(g©©)ĄČŲ¼╔Ž╦Ų║§ėąā╔ēK ASICĪŻė╔ė┌├┐éĆ(g©©)ÖC(j©®)╝▄┼õéõ┴╦ 72 ēK GPUŻ¼▀@ĘN┼õų├ūī╬ęéāĖąėXėąą®Ųµ╣ųĪŻ
ĪĪĪĪūŅ║åå╬Ą─ĮŌßī╩ŪŻ¼▒M╣▄ėą 5 éĆ(g©©)Į╗ōQĄČŲ¼Ż¼Ą½īŹ(sh©¬)ļH╔Žų╗ėą 9 éĆ(g©©)Į╗ōQ ASICĪŻę¬īŹ(sh©¬)¼F(xi©żn)▀@ę╗³c(di©Żn)Ż¼├┐éĆ(g©©)Į╗ōQąŠŲ¼ąĶę¬ 144 éĆ(g©©) 800Gbps Č╦┐┌ĪŻ▀@ī”(du©¼)ė┌ęį╠½ŠW(w©Żng)üĒšf┬į’@▓╗īż│ŻŻ¼Ą½┼c Nvidia į┌Ųõ NVLink 5 Į╗ōQÖC(j©®)╔ŽĄ─ū÷Ę©ŽÓ▓Ņ¤oÄūŻ¼▒M╣▄ Nvidia ╩╣ė├Ą─ ASIC öĄ(sh©┤)┴┐╩Ū NVLink 5 Ą─ā╔▒ČŻ¼Ä¦īÆģsų╗ėą NVLink 5 Ą─ę╗░ļĪŻ
ĪĪĪĪŲõĮY(ji©”)╣¹īó╩Ū┼c Nvidia Ą─ NVL72 ĘŪ│ŻŽÓ╦ŲĄ─═ž?f©┤)õĮY(ji©”)śŗ(g©░u)ĪŻ

ĪĪĪĪ╝¼╩ųĄ─╩ŪŻ¼ų┴╔┘ō■(j©┤)╬ęéā╦∙ų¬Ż¼─┐Ū░▀Ćø]ėą─▄ē“╠ß╣®▀@ĘNĦīÆ╦«ŲĮĄ─Į╗ōQÖC(j©®)ASICĪŻÄūų▄Ū░╬ęéā╔Ņ╚ļ蹊┐▀^Ą─▓®═©Tomahawk 6Ż¼Ųõąį─▄ūŅĮėĮ³Ż¼ōĒėąČÓ▀_(d©ó)128éĆ(g©©)800GbpsČ╦┐┌║═102.4TbpsĄ─┐éĦīÆĪŻ
ĪĪĪĪąĶ꬚f├„Ą─╩ŪŻ¼╬ęéā▓╗ų¬Ą└ AMD ╩Ūʱį┌ Helios ųą╩╣ė├┴╦ Broadcom——╦³ŪĪ║├╩Ū╔┘öĄ(sh©┤)ÄūéĆ(g©©)╣½ķ_┼¹┬ČĄ─ĘŪ Nvidia 102.4Tbps Į╗ōQÖC(j©®)ų«ę╗ĪŻ
ĪĪĪĪĄ½╝┤╩╣ Helios ╚¹▀M(j©¼n)┴╦ 10 Ņw▀@śėĄ─ąŠŲ¼Ż¼─Ń╚į╚╗ąĶę¬┴Ē═Ō 16 éĆ(g©©) 800Gbps ęį╠½ŠW(w©Żng)Č╦┐┌▓┼─▄▀_(d©ó)ĄĮ AMD ą¹ĘQĄ─ 260TB/s ĦīÆĪŻ▀@ĄĮĄū╩Ūį§├┤╗ž╩┬─ž?
ĪĪĪĪ╬ęéā▓┬£y Helios ╩╣ė├Ą─═ž?f©┤)õĮY(ji©”)śŗ(g©░u)┼c Nvidia Ą─ NVL72 ▓╗═¼ĪŻį┌ Nvidia Ą─ÖC(j©®)╝▄╩Į╝▄śŗ(g©░u)ųąŻ¼GPU ═©▀^ NVLink Į╗ōQÖC(j©®)ŽÓ╗ź▀BĮėĪŻ
ĪĪĪĪ╚╗Č°Ż¼┐┤ŲüĒ AMD Ą─ Helios ėŗ(j©¼)╦ŃĄČŲ¼īó▒Ż┴¶ MI300 ŽĄ┴ąĄ─ąŠŲ¼ĄĮąŠŲ¼ŠW(w©Żng)Ė±Ż¼▒M╣▄ėą╚²éĆ(g©©)ŠW(w©Żng)Ė±µ£Įėīó├┐éĆ(g©©) GPU ▀BĮėĄĮŲõ╦¹╚²éĆ(g©©)ĪŻ
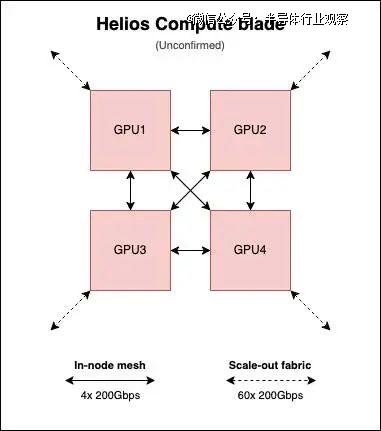
ĪĪĪĪ«ö(d©Īng)╚╗Ż¼▀@Č╝ų╗╩Ū▓┬£yŻ¼Ą½öĄ(sh©┤)ūų┤_īŹ(sh©¬)ŽÓ«ö(d©Īng)╬Ū║ŽĪŻ
ĪĪĪĪĖ∙ō■(j©┤)╬ęéāĄ─╣└╦ŃŻ¼├┐éĆ(g©©) GPU ×ķ╣Ø(ji©”)³c(di©Żn)ā╚(n©©i)ŠW(w©Żng)Ė±Ęų┼õ 600GB/s(12 Śl 200Gbps µ£┬Ę)Ą─ļpŽ“ĦīÆŻ¼▓ó×ķöU(ku©░)š╣ŠW(w©Żng)Įj(lu©░)Ęų┼õ╝s 3TB/s(60 Śl 200Gbps µ£┬Ę)Ą─ĦīÆĪŻę▓Š═╩ŪšfŻ¼├┐éĆ(g©©)Į╗ōQĄČŲ¼Ą─ĦīÆ╝s×ķ 600GB/sĪŻ
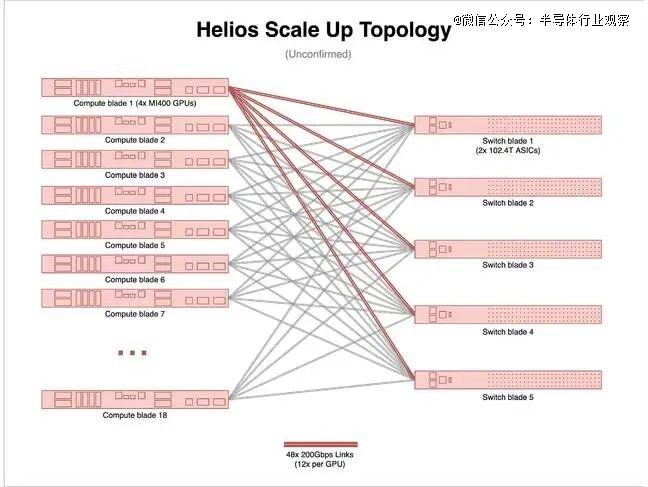
ĪĪĪĪ╚ń╣¹─·ėXĄ├Č╦┐┌öĄ(sh©┤)┴┐╠½ČÓŻ¼╬ęéāŅA(y©┤)ėŗ(j©¼)├┐éĆ(g©©)ėŗ(j©¼)╦ŃĄČŲ¼īóŠ█║Ž│╔┤¾╝s 60 éĆ(g©©) 800Gbps Č╦┐┌Ż¼╔§ų┴┐╔─▄ 30 éĆ(g©©) 1.6Tbps Č╦┐┌ĪŻ▀@ėą³c(di©Żn)ŅÉ╦Ųė┌ėó╠žĀ¢ī”(du©¼)ŲõGaudi3 ŽĄĮy(t©»ng)Ą─ū÷Ę©ĪŻō■(j©┤)╬ęéā┴╦ĮŌŻ¼īŹ(sh©¬)ļH▓╝ŠĆīó╝»│╔ĄĮ├ż▓Õ╩Į▒│░ÕųąŻ¼Š═Ž± Nvidia Ą─ NVL72 ŽĄĮy(t©»ng)ę╗śėĪŻ╦∙ęįŻ¼╚ń╣¹─·ų«Ū░▀Ćį┌×ķ╩ųäė(d©░ng)▀BĮėÖC(j©®)╝▄ŠW(w©Żng)Įj(lu©░)Č°¤®É└Ż¼¼F(xi©żn)į┌─·┐╔ęįĘ┼ą─┴╦ĪŻ
ĪĪĪĪ╬ęéā┐╔ęį┐┤ĄĮ▀@ĘNĘĮĘ©Ą─ę╗ą®║├╠ÄĪŻ╚ń╣¹╬ęéāĄ─ŅA(y©┤)£yš²┤_Ż¼─Ū├┤├┐éĆ(g©©) Helios ėŗ(j©¼)╦ŃĄČŲ¼Č╝┐╔ęį¬Ü(d©▓)┴ó▀\(y©┤n)ąąĪŻ┼c┤╦═¼Ģr(sh©¬)Ż¼Nvidia ėąę╗éĆ(g©©)å╬¬Ü(d©▓)Ą─ SKUŻ¼├¹×ķ GB200 NVL4Ż¼īŻķTßśī”(du©¼) HPC æ¬(y©®ng)ė├Ż¼╦³īó╦─éĆ(g©©) Blackwell GPU ▀BĮėį┌ę╗ŲŻ¼ŅÉ╦Ųė┌╔ŽłDŻ¼Ą½▓╗ų¦│ų╩╣ė├ NVLink ▀M(j©¼n)ąąöU(ku©░)š╣ĪŻ
ĪĪĪĪĄ½═¼śėŻ¼╬ęéā¤oĘ©▒ŻūC▀@Š═╩Ū AMD š²į┌ū÷Ą─╩┬Ūķ——▀@ų╗╩Ū╬ęéāūŅ ║├Ą─▓┬£yĪŻ
ĪĪĪĪ04
ĪĪĪĪöU(ku©░)┤¾ęÄ(gu©®)─Ż▓ó▓╗ęŌ╬Čų°═Żų╣öU(ku©░)┤¾ęÄ(gu©®)─Ż
ĪĪĪĪ─·┐╔─▄Ģ■(hu©¼)šJ(r©©n)×ķŻ¼AMD ║═ Nvidia Ą─ÖC(j©®)╝▄╩Į╝▄śŗ(g©░u)╦∙ų¦│ųĄ─Ė³┤¾Ą─ėŗ(j©¼)╦Ńė“ęŌ╬Čų°ęį╠½ŠW(w©Żng)ĪóInfiniBand ╗“ OmniPath — — ╩ŪĄ─Ż¼╦³éā╗žüĒ┴╦! — — īó═╦Šė┤╬ꬥž╬╗ĪŻ
ĪĪĪĪīŹ(sh©¬)ļH╔ŽŻ¼▀@ą®┐╔öU(ku©░)š╣ŠW(w©Żng)Įj(lu©░)¤oĘ©öU(ku©░)š╣ĄĮÖC(j©®)╝▄ų«═ŌĪŻNvidia Ą─ NVL72 ║═ AMD Ą─ Helios Ą╚ŽĄĮy(t©»ng)ųą╩╣ė├Ą─Ń~┘|(zh©¼)┐ńĮėļŖ└|Ė∙▒Š¤oĘ©▀_(d©ó)ĄĮ─Ū├┤▀h(yu©Żn)ĪŻ
ĪĪĪĪš²╚ń╬ęéāų«Ū░╦∙╠ĮėæĄ─Ż¼╣Ķ╣Ōūė╝╝ąg(sh©┤)ėąØō┴”Ė─ūā▀@ę╗¼F(xi©żn)ĀŅŻ¼Ą½įō╝╝ąg(sh©┤)į┌╝»│╔ĘĮ├µę▓├µ┼Rų°ūį╔ĒĄ─šŽĄKĪŻ╬ęéāšJ(r©©n)×ķŻ¼Nvidia ▓óĘŪ│÷ė┌ūį╔ĒęŌįĖČ°ęÄ(gu©®)äØ 600kW ÖC(j©®)╝▄Ą─░l(f©Ī)š╣┬ĘŠĆŻ¼Č°╩Ūę“?y©żn)ķ╦³ŅA(y©┤)ėŗ(j©¼)▀@ą®ęÄ(gu©®)─Ż╗»ŠW(w©Żng)Įj(lu©░)ö[├ōÖC(j©®)╝▄╩°┐`╦∙ąĶĄ─╣Ōūė╝╝ąg(sh©┤)īó¤oĘ©╝░Ģr(sh©¬)│╔╩ņĪŻ
ĪĪĪĪę“┤╦Ż¼╚ń╣¹─·ąĶę¬│¼▀^ 72 éĆ(g©©) GPU(╚ń╣¹─·š²į┌▀M(j©¼n)ąą╚╬║╬ŅÉą═Ą─ė¢(x©┤n)ŠÜŻ¼─Ū┐ŽČ©ąĶę¬)Ż¼─·╚į╚╗ąĶę¬ę╗éĆ(g©©)ÖMŽ“öU(ku©░)š╣╝▄śŗ(g©░u)ĪŻīŹ(sh©¬)ļH╔ŽŻ¼─·ąĶę¬ā╔éĆ(g©©)ĪŻę╗éĆ(g©©)ė├ė┌ģf(xi©”)š{(di©żo)║¾Č╦Ą─ėŗ(j©¼)╦ŃŻ¼┴Ēę╗éĆ(g©©)ė├ė┌Ū░Č╦Ą─öĄ(sh©┤)ō■(j©┤)╠ß╚ĪĪŻ
ĪĪĪĪÖC(j©®)╝▄ęÄ(gu©®)─Ż╦Ų║§ę▓ø]ėą£p╔┘╦∙ąĶĄ─ÖMŽ“öU(ku©░)š╣ĦīÆĪŻų┴╔┘ī”(du©¼)ė┌Ųõ NVL72Ż¼Nvidia ▒Š┤·«a(ch©Żn)ŲĘ╚įłį(ji©Īn)│ų 1:1 Ą─ NIC ┼c GPU ▒╚└²ĪŻ═©│ŻŻ¼├┐éĆ(g©©)ĄČŲ¼▀ĆĢ■(hu©¼)┼õéõ┴Ē═Ōā╔éĆ(g©©) NIC ╗“öĄ(sh©┤)ō■(j©┤)╠Ä└Ēå╬į¬ (DPU) Č╦┐┌Ż¼ė├ė┌é„Įy(t©»ng)Ą─Ū░Č╦ŠW(w©Żng)Įj(lu©░)īóöĄ(sh©┤)ō■(j©┤)ęŲ╚ļ║═ęŲ│÷┤µā”(ch©│)Ą╚Ą╚ĪŻ
ĪĪĪĪ▀@ī”(du©¼)ė┌ė¢(x©┤n)ŠÜüĒšf║▄ėąęŌ┴xŻ¼Ą½╚ń╣¹─ŃĄ─╣żū„žō(f©┤)▌d┐╔ęį╚▌╝{į┌å╬éĆ(g©©) 72 GPU Ą─ėŗ(j©¼)╦Ń║═ā╚(n©©i)┤µė“ųąŻ¼─Ū├┤ī”(du©¼)ė┌═Ų└ĒüĒšf┐╔─▄▓óĘŪĮ^ ī”(du©¼)▒žę¬ĪŻäĪ═ĖŻ║│²ĘŪ─Ń▀\(y©┤n)ąąĄ─╩Ū─│éĆ(g©©)²ŗ┤¾Ą─īŻėą─Żą═Ż¼ŪęŲõ╝Ü(x©¼)╣Ø(ji©”)╔ą▓╗ŪÕ│■Ż¼Ę±ät─Ń║▄┐╔─▄┐╔ęįū÷ĄĮĪŻ
ĪĪĪĪ║├Ž¹Žó╩ŪŻ¼╬ęéāīóį┌╬┤üĒ 6 ĄĮ 12 éĆ(g©©)į┬ā╚(n©©i)┐┤ĄĮę╗ą®Ė▀╗∙öĄ(sh©┤)ķ_ĻP(gu©Īn)(high radix switches)▀M(j©¼n)╚ļ╩ął÷ĪŻ
ĪĪĪĪ╬ęéāęčĮø(j©®ng)╠ߥĮ▀^▓®═©Ą─Tomahawk 6Ż¼╦³īóų¦│ųÅ─64éĆ(g©©)1.6TbpsČ╦┐┌ĄĮ1024éĆ(g©©)100GbpsČ╦┐┌Ą─Ė„ĘNĦīÆĪŻ┤╦═ŌŻ¼ėóéź▀_(d©ó)Ą─Spectrum-X SN6810ę▓īóė┌├„─Ļ╔Ž╩ąŻ¼╦³īó╠ß╣®ČÓ▀_(d©ó)128éĆ(g©©)800GbpsČ╦┐┌Ż¼▓óīó▓╔ė├╣Ķ╣Ō╝╝ąg(sh©┤)ĪŻ┼c┤╦═¼Ģr(sh©¬)Ż¼ėóéź▀_(d©ó)Ą─SN6800īó┼õéõ512éĆ(g©©)MPOČ╦┐┌Ż¼├┐éĆ(g©©)Č╦┐┌╦┘┬╩┐╔▀_(d©ó)800GbpsĪŻ
ĪĪĪĪ▀@ą®Į╗ōQÖC(j©®)┤¾Ę∙£p╔┘┴╦┤¾ęÄ(gu©®)─Ż AI ▓┐╩╦∙ąĶĄ─Į╗ōQÖC(j©®)öĄ(sh©┤)┴┐ĪŻę¬ęį 400Gbps Ą─╦┘Č╚▀BĮė 128,000 éĆ(g©©) GPU ╝»╚║Ż¼┤¾╝sąĶę¬ 10,000 ┼_(t©ói) Quantum-2 InfiniBand Į╗ōQÖC(j©®)ĪŻČ°▀xō± 51.2Tbps ęį╠½ŠW(w©Żng)Į╗ōQÖC(j©®)Ż¼ät┐╔ęįėąą¦Ąžīó▀@ę╗öĄ(sh©┤)ūų£p░ļĪŻ
ĪĪĪĪļSų°▐D(zhu©Żn)Ž“ 102.4Tbps Į╗ōQŻ¼▀@éĆ(g©©)öĄ(sh©┤)ūų┐s£pĄĮ 2,500Ż¼╚ń╣¹─·┐╔ęį╩╣ė├ 200Gbps Č╦┐┌Ż¼ätų╗ąĶę¬ 750 éĆ(g©©)Ż¼ę“?y©żn)ķ╗∙ö?sh©┤)ūŃē“┤¾Ż¼─·┐╔ęį╩╣ė├ā╔īėŠW(w©Żng)Įj(lu©░)Ż¼Č°▓╗╩Ū╬ęéāį┌┤¾ą═ AI ė¢(x©┤n)ŠÜ╝»╚║ųąĮø(j©®ng)│Ż┐┤ĄĮĄ─╚²īė┼ųśõ═ž?f©┤)õĪ?/p>
ĪĪĪĪ╬─š┬ā╚(n©©i)╚▌āH╣®ķåūxŻ¼▓╗śŗ(g©░u)│╔═Č┘YĮ©ūhŻ¼šłųö(j©½n)╔„ī”(du©¼)┤²ĪŻ═Č┘Yš▀ō■(j©┤)┤╦▓┘ū„Ż¼’L(f©źng)ļU(xi©Żn)ūįō·(d©Īn)ĪŻ
║Żł¾(b©żo)╔·│╔ųą...

║Ż╦ćAIĄ──Żą═ŽĄĮy(t©»ng)į┌ć°ļH╩ął÷╔ŽÅV╩▄║├įu(p©¬ng)Ż¼─┐Ū░šŠā╚(n©©i)└█ėŗ(j©¼)─Żą═öĄ(sh©┤)│¼▀^80╚féĆ(g©©)Ż¼║Ł╔wīæīŹ(sh©¬)ĪóČ■┤╬į¬Īó▓Õ«ŗĪóįO(sh©©)ėŗ(j©¼)Īóözė░Īó’L(f©źng)Ė±╗»łDŽ±Ą╚ČÓŅÉą═æ¬(y©®ng)ė├ł÷Š░Ż¼╗∙▒ŠĖ▓╔w╦∙ėąų„┴„äō(chu©żng)ū„’L(f©źng)Ė±ĪŻ

9į┬9╚šŻ¼ć°ļHÖÓ(qu©ón)═■╩ął÷š{(di©żo)čąÖC(j©®)śŗ(g©░u)ėóĖ╗┬³(Omdia)░l(f©Ī)▓╝┴╦ĪČųąć°AIįŲ╩ął÷Ż¼1H25ĪĘł¾(b©żo)ĖµĪŻųąć°AIįŲ╩ął÷░ó└’įŲš╝▒╚8%╬╗┴ąĄ┌ę╗ĪŻ

9į┬24╚šŻ¼╚A×ķ└żņ`š┘ķ_Ī░ųŪ─▄¾w“×(y©żn)Ż¼ę╗Ų┴ĄĮ╬╗Ī▒╚A×ķIdeaHubŪ¦ąą░┘śI(y©©)¾w“×(y©żn)╣┘ėŗ(j©¼)äØ░l(f©Ī)▓╝Ģ■(hu©¼)ĪŻ

č┼±R╣■ū“╚šą¹▓╝═Ų│÷ā╔┐ŅŅ^┤„╩ĮČ·ÖC(j©®)Ż¼Ęųäe╩ŪŲĮ░Õš±─żĄ─YH-4000║═äė(d©░ng)╚”įŁ└ĒĄ─YH-C3000ĪŻ

IDCĮ±╚š░l(f©Ī)▓╝Ą─ĪČ╚½Ū“ųŪ─▄╝ęŠėŪÕØŹÖC(j©®)Ų„╚╦įO(sh©©)éõ╩ął÷╝ŠČ╚Ė·█Öł¾(b©żo)ĖµŻ¼2025─ĻĄ┌Č■╝ŠČ╚ĪĘ’@╩ŠŻ¼╔Ž░ļ─Ļ╚½Ū“ųŪ─▄╝ęŠėŪÕØŹÖC(j©®)Ų„╚╦╩ął÷│÷žø1,2╚f┼_(t©ói)Ż¼═¼▒╚į÷ķL33%Ż¼’@╩Š│÷ŲĘŅÉÅŖ(qi©óng)ä┼Ą─╩ął÷ąĶŪ¾ĪŻ


ĘĄ╗žų„Ēō ®« ĻP(gu©Īn)ė┌╬ęéā ®« ā╚(n©©i)╚▌┬ō(li©ón)ŽĄ ®« ┬ō(li©ón)ŽĄ╬ęéā ®« ├Ōž¤(z©”)┬Ģ├„ ®« įŁäō(chu©żng)ą┬┬ä ®« ķTæ¶░µ
Copyright www.9c1h.cn ųą╬─┐Ų╝╝┘YėŹ 2009-2025 all rights reserved ŠW(w©Żng)šŠ┬ō(li©ón)ŽĄ╬óą┼ xishuinet
ĻP(gu©Īn)µIį~Ż║CITNews|Citnewsųą╬─┐Ų╝╝┘YėŹ|ųą╬─┐Ų╝╝┘YėŹŠW(w©Żng)|┐Ų╝╝┘YėŹŠW(w©Żng)|ųąć°┐Ų╝╝┘YėŹ|ųąć°┐Ų╝╝ą┬┬äŠW(w©Żng)|ųąć°┐Ų╝╝┘YėŹŠW(w©Żng)|┐ņ┐Ų╝╝|ą┬┐Ų╝╝|ųą╬─┐Ų╝╝öĄ(sh©┤)┤aŅ^Śl╠¢(h©żo)|ųą╬─ęŲäė(d©░ng)ą┬├Į¾w
Š®ICPéõ18037198╠¢(h©żo)-1![]() Š®╣½ŠW(w©Żng)░▓éõ 11010502041587╠¢(h©żo)
Š®╣½ŠW(w©Żng)░▓éõ 11010502041587╠¢(h©żo)