ÀÀÀÀ§þäšêÒ°¢È˜OpenAIÕ_(k´Ài)åÇêùæŸÅô£ªò(zh´°n)y(c´´)å¥₤SimpleQAȘ¢èØåëøºÕ_(k´Ài)¯l(f´À)íÔïpùèzy(c´´)ÀÂÅÈò(zh´°n)ǵáÈÅëçáíÌ(sh´ˆ)ÅåáÉêÎÀÈ
ÀÀÀÀá¢ú¯È˜¤ÉÑÁǵáÈÅë±(hu´˜)°—˜F(xi´Ên)Ø£Ýƒí»§(j´ˋng)¤ºíf(shu´Ù)¯ùçâçá(w´´n)Ÿ}Șâ»àÓȘáÐäÃ(w´´n)NBAvòñèüçûñøæŸÑÁçáòúíl(shu´ˆ)Șù■£ÄÇÞòúÔ~¢ù äçÊȘ(sh´ˆ)ŠHèüòúâíý¥âòíýáñù¿Àȯ■â´OpenAIæ奤¯l(f´À)ý¥çáGPT-4oÀÂo1-previewÀÂo1miniçàú¯îÄáÈÅëÑ¥ÆÅÔ@Åˋ“£ûÆX(ju´Î)”ŠyŸ}ÀÈ
ÀÀÀÀùªØåȘSimpleQAÎ(du´˜)ÆÖÕ_(k´Ài)¯l(f´À)íÔÚ(l´Âi)íf(shu´Ù)Ș¢èØ僨ò(zh´°n)y(c´´)åǵáÈÅëáÉñþï°—í»Ç_çáÇÞ¯¡È˜ýÂÎ(du´˜)áÈÅëçáíf(shu´Ù)øeáÉêÎÔM(j´˜n)ÅÅÅÈò(zh´°n)ࣤµÔM(j´˜n)ÅÅǵñªÑà(y´Ùu)£₤ëõèóáÈÅëáÉêÎÀÈ
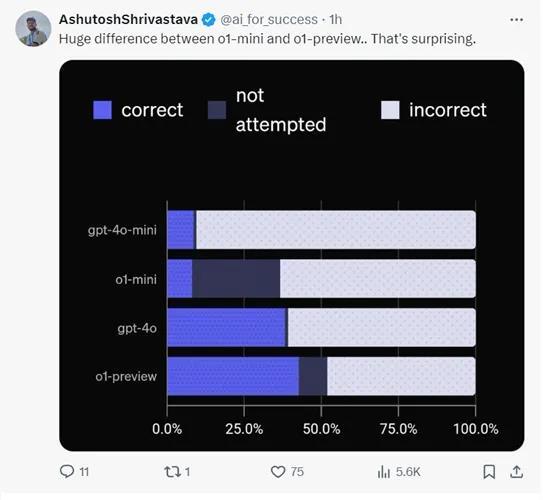
ÀÀÀÀÆŃW(w´Èng)ÆîÝÚòƒÈ˜¢ÇêùSimpleQAçáy(c´´)åç(sh´Ç)±(j´Ç)ýé¯l(f´À)˜F(xi´Ên)Șo1-mini¤ëo1-previewçáÅåáÉýŸƒÁÔ@ûÇǵȘo1-miniÔBGPT-4oѥǷý£Ô^(gu´¯)ÀÈ
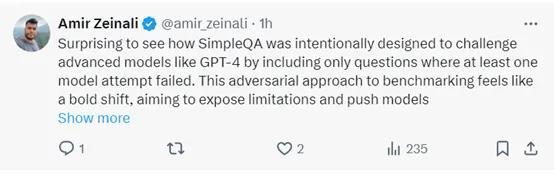
ÀÀÀÀêŸàùµ@Æ çáòúȘSimpleQA Ý£ÆÅØãåO(sh´´)Æ(j´˜)ÆûÚ(l´Âi)ä¶Þ(zh´Ên)üþ GPT-4Ô@Æçá¡Ô¥(j´ˆ)áÈÅëȘóðøÅø£¯■â´øêèìÆÅØ£ÇöáÈÅëLåòÏÀçá(w´´n)Ÿ}ÀÈÔ@ñNÎ(du´˜)¢¿Ååçᣪò(zh´°n)y(c´´)åñ§ñ´¡ÅÆX(ju´Î)üþòúØ£ñNǵáçáßD(zhu´Èn)æȘø¥åÖ§ØòƒáÈÅëçáƒøüßÅåýÂëóÆ(d´¯ng)áÈÅëçá¯l(f´À)í¿ÀÈ
ÀÀÀÀÑÁí«Õ_(k´Ài)åÇÔ@òú¤ûòôÀÈeë■êùáÐû«æøçá°¾øå¯À~

ÀÀÀÀÔ@¤ÉÆÅàÊȘ±(hu´˜)¢Ç秡■ÑÁçááÈÅëÝ£y(c´´)åȘØ奯ù■écöØåÖäÿˋçáöá݃èüÔM(j´˜n)ÅÅçáä(g´¯u)/£ûÆX(ju´Î)£ªò(zh´°n)y(c´´)å§Y(ji´Î)¿«çáÝàï^ÀÈ
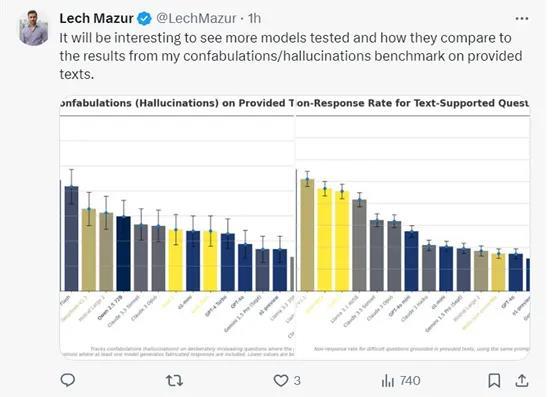
ÀÀÀÀ¤ÉüŠ¢Ç¢Ço1áÈÅëçáëõí«¯Ìy(c´´)åÀÈ

ÀÀÀÀëõà¨ë˜Øãòô(sh´ˆ)ÅååÖàù¿ÊøúáÉøÅçáøÄ؈ÅåÀÈSimpleQA çáØ»àŠ¢èØåÿ@ø½äÃè»öØÎ(du´˜)íZ(y´°)îåáÈÅëåÖÔ@Ø£ŸI(l´¨ng)Æ·ÝÚ˜F(xi´Ên)çáâÚ§ãÀÈÔ@òúØ£Ú(xi´Êng)¥¯r(sh´ˆ)çáéeNJȘò(zh´°n)Ç_çáç(sh´Ç)±(j´Ç)Î(du´˜)ÆÖÅéàöàù¿ÊøúáÉüç§y(t´₤ng)øêõP(gu´Àn)øÄ؈ÀÈóÖÇ»¢Çç§Ô@(g´´)£ªò(zh´°n)y(c´´)åçáƯÚÀÈ
ÀÀÀÀÔ@¤ÉøÄ؈Șط?y´Ên)ÕÇ_ÝÈǵáÈÅëçáòô(sh´ˆ)ÅåÎ(du´˜)ÆÖñâø¿Íe(cu´¯)í`ÅéüÂçá¼ýËøêõP(gu´Àn)øÄ؈Șѽ SimpleQA äÿˋêùØ£ñNù(bi´Ào)ò(zh´°n)£₤çáñ§ñ´Ú(l´Âi)åu(p´ˆng)¿â¤ë¡áÔM(j´˜n)áÈÅë¢è¢¢ÅåçáÔ@Ø£õP(gu´Àn)ÌIñ§ûÌÀÈ
ÀÀÀÀ¤É¯¶È˜øÄ؈çá¡■Åô!

ÀÀÀÀSimpleQA¤(ji´Èn)ö§Õ§B
ÀÀÀÀåÖç(sh´Ç)±(j´Ç)òí¥₤ŠAÑöȘSimpleQAçá(w´´n)Ÿ} ¢¥ÇÞ¯¡Æèèû«ˆ(d´ý)êÂçá AI Æ(x´Çn)ƒTÇ_ѴȘýÂúØÆ(x´Çn)ƒTåÖ(chu´Êng)§´(w´´n)Ÿ}r(sh´ˆ)ݣ؈úµäÿˋøÏ°øÇÞ¯¡çáƒW(w´Èng)Ú(y´´)̧ÆȘØåÇ_ÝÈÇÞ¯¡ÆŢ袢çáØâ±(j´Ç)ÀÈ
ÀÀÀÀâ»àÓȘÎ(du´˜)ÆÖ “íl(shu´ˆ)òúäO(p´ˆng)¿«¿¨ùƒçá(chu´Êng)ò¥àùøÛØ£” Ô@Æ°ÈæR(sh´ˆ)Åå(w´´n)Ÿ}ȘÆ(x´Çn)ƒT±(hu´˜)¡ª±(j´Ç)vòñìYêü¤ë¿ìñ§ÅéüÂÇ_Ñ´ÇÞ¯¡Õ òñçìñ·äý¥ù¿çàȘý¡§èüàÓäO(p´ˆng)¿«¿¨ùƒ¿ìñ§ƒW(w´Èng)íƒçàüÁõP(gu´Àn)̧Ææ¼ÕæC±(j´Ç)ÀÈ
ÀÀÀÀë˜r(sh´ˆ)Ș(w´´n)Ÿ}çáåO(sh´´)Æ(j´˜)ò¿çûŸA(y´Ç)y(c´´)ÇÞ¯¡ØæÆÖåu(p´ˆng)¿âȘø£åòåSÆÅØ£(g´´)û¼Ç_úØo(w´ý)¢è (zh´Ëng)æhçáÇÞ¯¡È˜ÝÉûãêùáȤ»Åå¤ëóÓêxÅåÀÈÝààÓ “ááØ£áõ iPhone òæÇö¯l(f´À)ý¥”ȘÇÞ¯¡û¼Ç_Õ“2007áõ”Șѽý£òúØ£(g´´)ñѺ£·áȤ»çáÝÚò—ÀÈ
ÀÀÀÀSimpleQAçáåu(p´ˆng)¿â(w´´n)Ÿ}¤ëÇÞ¯¡Ñ¥ñú°È¤(ji´Èn)ÑäȘÔ@ò¿çûÔ\(y´Çn)ÅÅùìÑ࢚úØýì漤(ji´Èn)öÀÈåÖåu(p´ˆng)¿âáÈÅë£ÄÇÞr(sh´ˆ)Șë´Ô^(gu´¯) OpenAI APIÔM(j´˜n)ÅÅåu(p´ˆng)ñøØýòÛñøî¡ùìÀÈç(sh´Ç)±(j´Ç)¥₤øů■¤˜4326(g´´)(w´´n)Ÿ}ȘáÉ·åÖأѴ°äÑàèü§ççëý£ë˜ÇöÔ\(y´Çn)ÅÅøÛÕgçáñ§ýŸÈ˜ò¿åu(p´ˆng)¿â§Y(ji´Î)¿«¡■¥Æñ(w´Ïn)Ñ´¢è¢¢ÀÈ
ÀÀÀÀâ»àÓȘåÖÎ(du´˜)ÑÁ(g´´)áÈÅëÔM(j´˜n)ÅÅy(c´´)år(sh´ˆ)Șý£±(hu´˜)Ø·?y´Ên)Õ?sh´Ç)±(j´Ç)¥₤݃èÚçáý£ñ(w´Ïn)Ñ´ÅåѽÏ(d´Èo)øô§Y(ji´Î)¿«°—˜F(xi´Ên)ï^ǵý´Æ(d´¯ng)ȘáѽáÉ·¡■ò(zh´°n)Ç_çÄÝàï^áÈÅëøÛÕgçáÅåáÉýŸÛÀÈ
ÀÀÀÀSimpleQAçáåu(p´ˆng)¿â¥₤ñú°ÈÑÁ刣₤ÀȤÙèwvòñÀ¢óW(xu´Î)¥¥Åg(sh´Ç)ÀÂùÅg(sh´Ç)ÀÂçÄâÚÀŠؿ(ji´Î)á¢çàÑÁ(g´´)ŸI(l´¨ng)Æ·ÀÈÔ@ñNÑÁÆÅåò¿çûåu(p´ˆng)¿â§Y(ji´Î)¿«¡■ƒÔóíÝÕÅå¤ëǺÝÚÅåȘáÉ·à¨ûÌçÄz·(y´Ên)?z´Ài)ÈÅëåÖý£ë˜øˆæR(sh´ˆ)ŸI(l´¨ng)Æ·çáòô(sh´ˆ)Åå£ÄÇÞáÉêÎÀÈ
ÀÀÀÀêÚØ£(g´´)¤ûäòúù■çáÅÈò(zh´°n)y(c´´)ꢿÎáÉÀÈë´Ô^(gu´¯)å(x´ýn)(w´´n)áÈÅëÎ(du´˜)óðÇÞ¯¡çáÅéÅáȘîŃ¢íÔ¢èØåêù§ãáÈÅëòúñþøˆçâù■øˆçâòýûÇȘÔ@òúØ£(g´´)¤ÉøÄ؈çáÅÈò(zh´°n)˜F(xi´Ên)üµÀÈàÓ¿«Ø£(g´´)áÈÅëáÉ·ò(zh´°n)Ç_çÄåu(p´ˆng)¿âæ奤çáÅéÅáùÛó§È˜áúûÇù■ƒëòúØ£(g´´)ÅÈò(zh´°n)ꥤûçááÈÅëÀÈ
ÀÀÀÀOpenAIë´Ô^(gu´¯)SimpleQAÎ(du´˜)GPT-4oÀÂo1-previewÀÂo1miniÀÂClaude-3-haikuÀÂClaude-3-sonnetçàú¯îÄáÈÅëÔM(j´˜n)ÅÅêùƒC¤üy(c´´)åÀȧY(ji´Î)¿«ÿ@òƒÈ˜ï^ǵáÈÅë봰ȃÔÆÅ¡■¡ÔçáÅåáÉȘ稥Çò¿òúú¯îÄáÈÅëåÖSimpleQA èüçáÝÚ˜F(xi´Ên)ØýýÂñúëõûâÀÈ
ÀÀÀÀâ»àÓȘGPT -4o åÖ£ÄÇÞØ£Åˋ(w´´n)Ÿ}r(sh´ˆ)áÉ·§o°—ï^¡ÔÝàâ»çáí»Ç_ÇÞ¯¡È˜ç¨àåÆÅý¢ñøÍe(cu´¯)í`£ÄÇÞ¤ëöÇLå£ÄÇÞçáúÕrÀÈë˜r(sh´ˆ)Șë´Ô^(gu´¯)y(c´´)ê¢áÈÅëçáÅÈò(zh´°n)úÕrȘ¯l(f´À)˜F(xi´Ên)áÈÅëŠmà£ÆÅأѴçáÅéÅá¡éáŸÈ˜ç¨óíÝÕÇÌåÖ¡Ô¿âæ奤ÅéÅáçá(w´´n)Ÿ}ȘáÈÅëçáÅéÅáùÛó§éc(sh´ˆ)ŠH£ÄÇÞçáò(zh´°n)Ç_ÅåøÛÕgÇÌåÖýŸƒÁÀÈ
ÀÀÀÀöáíôà(n´´i)àïH¿ˋÕæxȘý£(g´¯u)°èëÑìY§´æhȘí(q´¨ng)ø(j´¨n)è¼Î(du´˜)Ç»ÀÈëÑìYíÔ±(j´Ç)Çùýìæ¼È˜ÿL(f´Ëng)ŠU(xi´Èn)æåº(d´Àn)ÀÈ
¤Èµ(b´Êo)躰èøÅ...

¤ÈùAIçááÈÅëüç§y(t´₤ng)åÖ½(gu´Û)ŠHòÅ—(ch´Èng)èüVòɤûåu(p´ˆng)Șá¢ú¯íƒà(n´´i)âÜÆ(j´˜)áÈÅëç(sh´Ç)°˜Ô^(gu´¯)80àf(w´Ên)(g´´)Ș¤Ùèw(xi´Ï)(sh´ˆ)ÀÂѱÇöåˆÀÂýÍÛ(hu´Ê)ÀÂåO(sh´´)Æ(j´˜)ÀÂzƯÀÂÿL(f´Ëng)¡þ£₤DüþçàÑÁŸ(l´´i)Åëˆ(y´ˋng)Æû—(ch´Èng)ƒ¯È˜£ªÝƒ¡ýèwùªÆÅø¼ê¼(chu´Êng)æ¼ÿL(f´Ëng)¡þÀÈ

9åô9àíȘ½(gu´Û)ŠHÁ(qu´Ân)ë±òÅ—(ch´Èng)í{(di´Êo)îÅC(j´ˋ)(g´¯u)Æ¡£ô■(Omdia)¯l(f´À)ý¥êùÀÑøŽ(gu´Û)AIåóòÅ—(ch´Èng)Ș1H25Àñµ(b´Êo)¡ÌÀÈøŽ(gu´Û)AIåóòÅ—(ch´Èng)¯Ââÿåóí¥Ýà8%ö£êÅçÖØ£ÀÈ

9åô24àíȘàAÕâÊš`íìÕ_(k´Ài)À¯øúáɵw·(y´Ên)Șأóêç§ö£ÀÝàAÕIdeaHubúÏÅůìI(y´´)µw·(y´Ên)¿ìÆ(j´˜)¯l(f´À)ý¥±(hu´˜)ÀÈ

îéþR¿±æ·àíÅ«ý¥ëó°—袟Ÿ^Ǽò§ÑºC(j´ˋ)Șñøeòúó§¯ÍíþáÊçáYH-4000¤ëÆ(d´¯ng)àÎåÙâÚçáYH-C3000ÀÈ

IDC§þàí¯l(f´À)ý¥çáÀÑà¨ú·øúáɥ؃ÆúÍC(j´ˋ)ó¼àùåO(sh´´)ðòÅ—(ch´Èng)¥ƒÑࡺܵ(b´Êo)¡ÌȘ2025áõçÖѱ¥ƒÑàÀñÿ@òƒÈ˜èü¯Šáõà¨ú·øúáɥ؃ÆúÍC(j´ˋ)ó¼àùòÅ—(ch´Èng)°—Ä1,2àf(w´Ên)é_(t´Âi)Șë˜Ýàå—ÕL(zh´Èng)33%Șÿ@òƒ°—óñŸ(l´´i)(qi´Âng)éçáòÅ—(ch´Èng)ÅÒúµÀÈ


ñç£Äø¼Ú(y´´) ˋÛ õP(gu´Àn)ÆÖöØ ˋÛ à(n´´i)àïô(li´Ân)üç ˋÛ ô(li´Ân)üçöØ ˋÛ ûãÄ(z´Î)ôû¼ ˋÛ åÙ(chu´Êng)Åôô ˋÛ ÕT(m´În)¶(h´Ç)¯Ì
Copyright www.9c1h.cn øÅöá¢ó¥¥ìYÆ 2009-2025 all rights reserved ƒW(w´Èng)íƒô(li´Ân)üçöÂÅé xishuinet
õP(gu´Àn)ÌIå~ȤCITNews|CitnewsøÅöá¢ó¥¥ìYÆ|øÅöá¢ó¥¥ìYƃW(w´Èng)|¢ó¥¥ìYƃW(w´Èng)|øŽ(gu´Û)¢ó¥¥ìYÆ|øŽ(gu´Û)¢ó¥¥ÅôôƒW(w´Èng)|øŽ(gu´Û)¢ó¥¥ìYƃW(w´Èng)|¢š¢ó¥¥|Åô¢ó¥¥|øÅöá¢ó¥¥ç(sh´Ç)ÇaŸ^lä(h´Êo)|øÅöáØóÆ(d´¯ng)Åôû§µw
ƒˋICPð18037198ä(h´Êo)-1![]() ƒˋ¿¨ƒW(w´Èng)¯ýð 11010502041587ä(h´Êo)
ƒˋ¿¨ƒW(w´Èng)¯ýð 11010502041587ä(h´Êo)